
 作者介绍:TigerHu,某在线教育企业大数据营销产品负责人,主导数据产品线和营销 CRM 产品线。
作者介绍:TigerHu,某在线教育企业大数据营销产品负责人,主导数据产品线和营销 CRM 产品线。
本文内容均从作者真实实践过程出发,结合在线教育业务背景和当时的客观条件,深入分析大数据营销平台实战,尽可能详细地为大家阐述企业数据化之路由底层建设到 MVP 方案,再到推广落地的完整过程。
本期分享侧重于大数据营销平台的搭建。以下为正文:
在构建大数据平台之前,需要进行充分调研,找准问题才能对症下药。对企业数据化程度的评估方法,可以参考下图所示的数据管理能力成熟度模型(DMM):  在对企业内部数据问题进行全面诊断和剖析后,接下来要针对这些问题给出解决的架构方案和路线图。
在对企业内部数据问题进行全面诊断和剖析后,接下来要针对这些问题给出解决的架构方案和路线图。
(1)数据服务体系蓝图
从业务视角来看,数据服务体系需要覆盖完整的公司业务、贯穿业务的各个阶段并伴随企业发展。 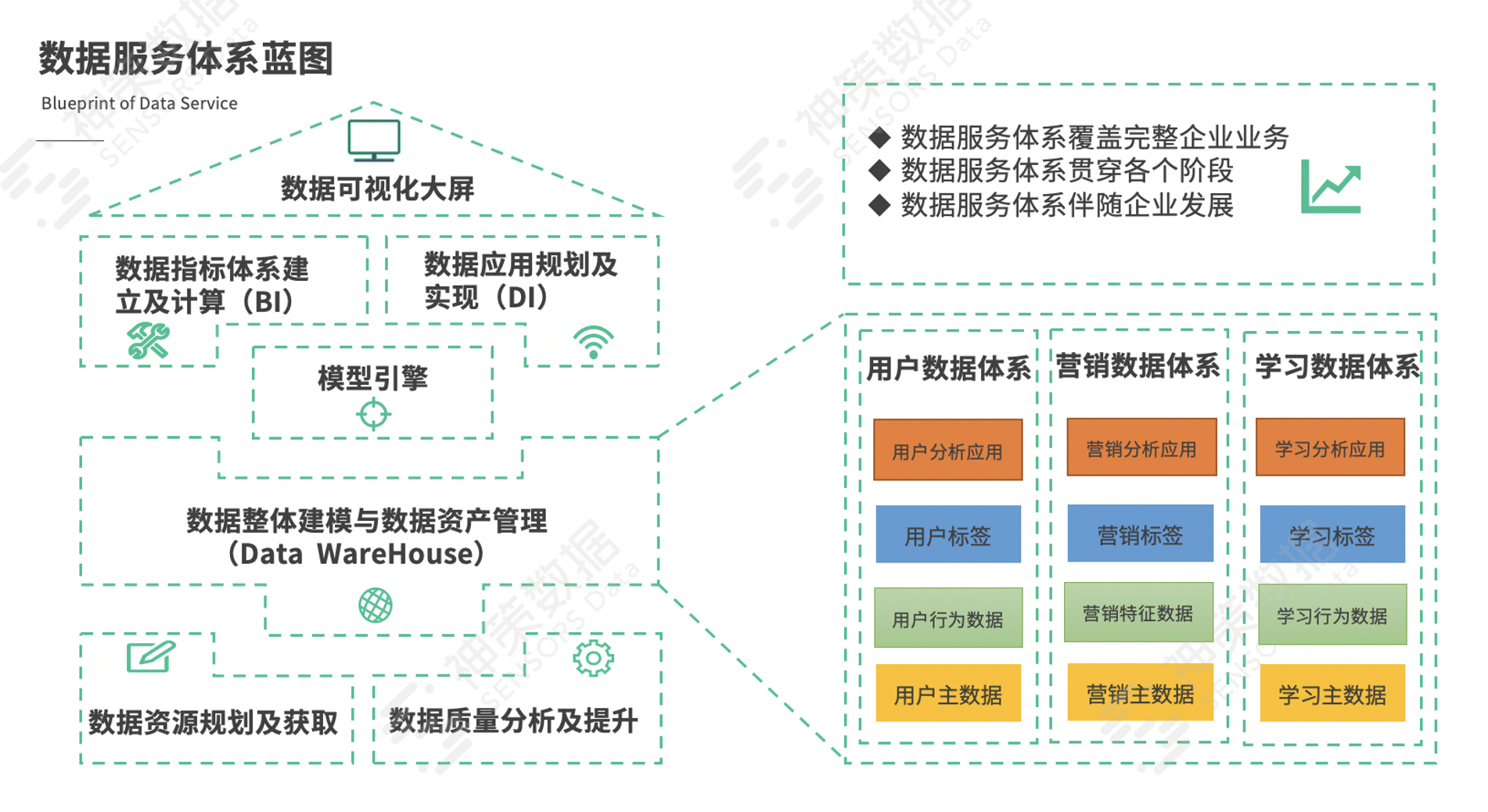 在此数据服务体系中,处于核心环节的是数据整体建模和数据资产管理,也就是大家熟悉的统一化数仓建设。结合在线教育业务特点,作者认为数仓建设需要满足三个核心数据体系:
在此数据服务体系中,处于核心环节的是数据整体建模和数据资产管理,也就是大家熟悉的统一化数仓建设。结合在线教育业务特点,作者认为数仓建设需要满足三个核心数据体系:
· 用户数据体系:用户分析应用、用户标签、用户行为数据、用户基本信息主数据等;
· 营销数据体系:营销分析应用、营销分层标签、渠道特征数据、营收转化相关的主数据等;
· 学习数据体系:学习分析应用、学习偏好标签、学习行为数据、学习素材基础数据等。
(2)数据仓库架构
数据仓库的层次划分采用业界通用的层级划分方式,包括:ODS、DWD、DWS、ADS 层,如下图所示:  (3)数据处理流程架构
(3)数据处理流程架构
数据处理流程主要包括源数据同步清洗、数据处理加工、模型运算和数据应用。基于在线教育公司的业务特点,作者总结出源数据主要包括:渠道数据、用户数据、交易数据、营销过程数据、学习数据、外部第三方数据等。
模型引擎包括离线计算引擎和实时计算引擎两类,需要满足算法(或规则)部署、模型训练和上线、以及对其他业务系统提供接口服务的能力,比如为 CRM 系统提供多算法的线索实时分配、用户画像分层等服务。在数据的汇聚、加工生产、应用的全流程中,全生命周期的数据治理不能忽视,因为数据的准确性、完整性、一致性直接影响业务对数据系统的可信度。 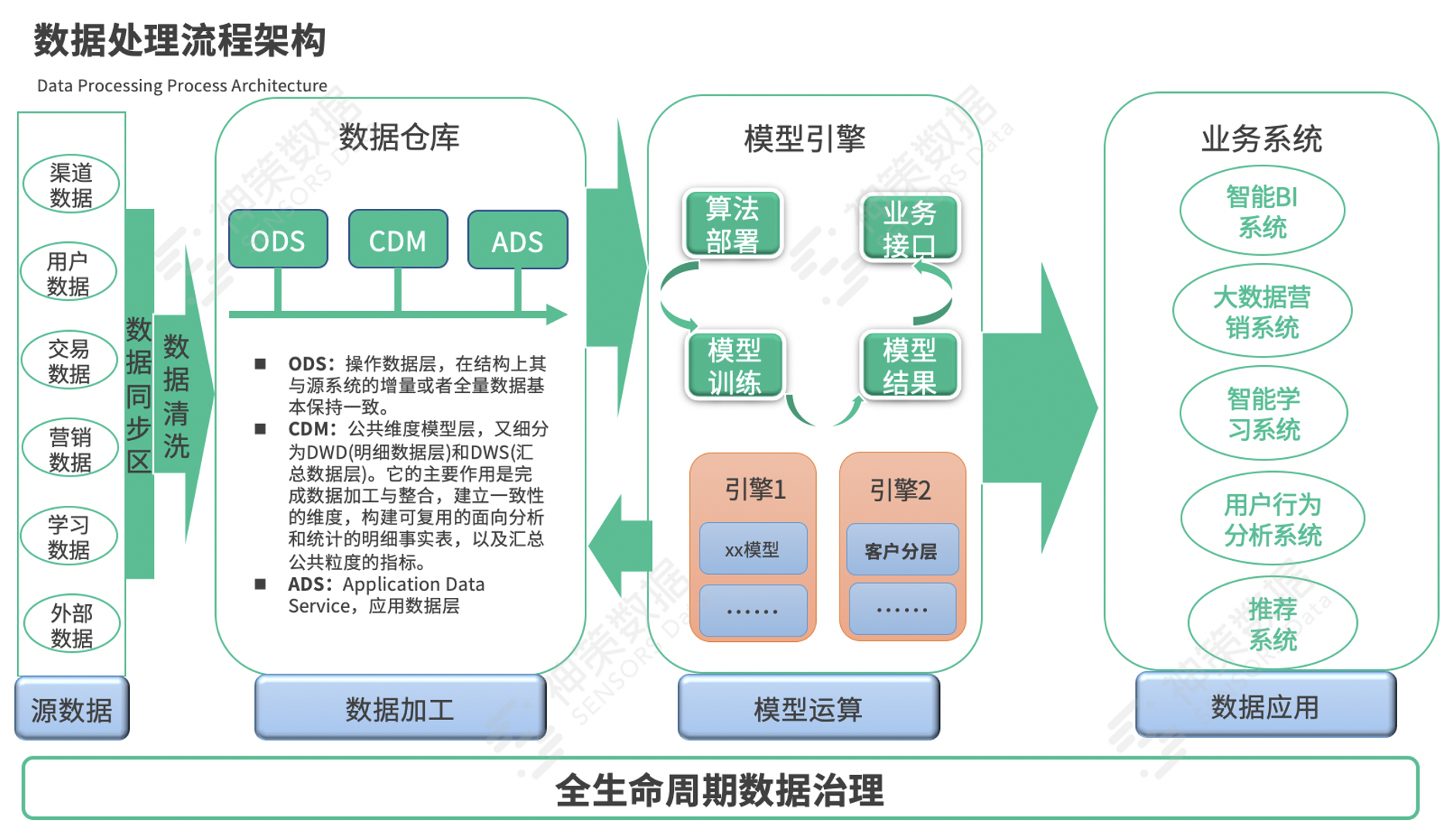 (4)从 0~1 构建大数据平台的 Road Map
(4)从 0~1 构建大数据平台的 Road Map
结合推进大数据平台建设过程中的经验,作者总结出以下线路图: 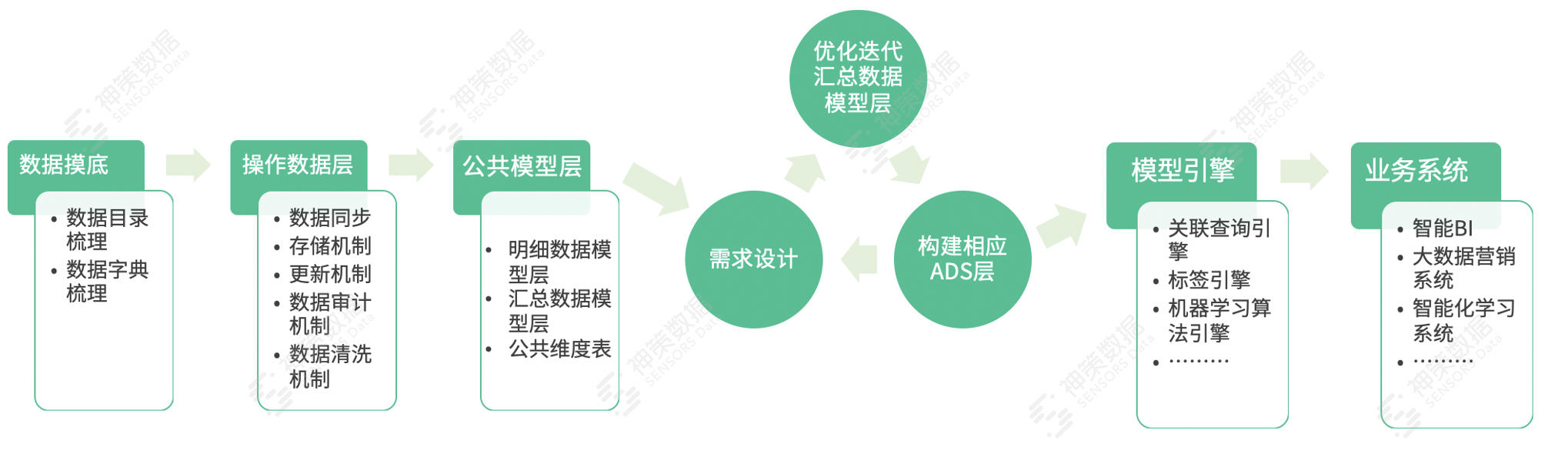 常见的数据模型有星型模型、雪花模型和星座模型三种,数据仓库设计一般采用星型模型,它是一种多维的数据关系,由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据。
常见的数据模型有星型模型、雪花模型和星座模型三种,数据仓库设计一般采用星型模型,它是一种多维的数据关系,由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据。
大数据平台的构建是从底层解决业务面临的数据问题,一定是需要一个时间周期的,因此其对业务的贡献不会立刻显现,而业务感知不到数据的赋能势必会影响老板对数据团队的资源投入,怎么解决这个死循环?下面作者将详细阐述在该在线教育企业数据化能力构建初期,如何利用神策分析和内部数仓的结合来构建支撑数据化运营平台的 MVP 方案。
一、初期痛点及神策解决方案
通过对企业内部业务人员的访谈调研,作者发现当时在用户数据的使用层面主要存在三个痛点:用户行为数据缺失、用户渠道效果无法全流程分析、不同运营角色个性化分析需求较多。
1.过程数据缺失
在管理决策层面老板和各部门老大只能拿到结果数据,比如注册用户信息、交易数据等。
熟悉运营工作的读者都清楚,用户运营一定是在特定的业务场景下以一系列运营环节的达成为闭环的。比如在线教育常见的营销场景下交易的达成环节为“报名-入群-开营-课程体验-课程报名”,再比如,对于 App 运营用户交易达成的最短路径为“打开 App-首页-考试频道页-课程详情页-立即购买-支付订单”。如果在决策者的案头上只有结果性数据而缺乏过程数据,那么决策者对问题的定位和分析一定是不全面的,难免会陷入盲人摸象的困局。
神策数据提供了一整套数据埋点解决方案,包括:全埋点、前后端代码埋点、可视化全埋点等,并且其 SDK 也做了开源贡献,埋点技术成熟度得到业界认可。采用神策分析,有利于实现不同业务场景下的过程数据埋点全覆盖。
2.渠道效果难以全方位追溯
该在线教育企业外部渠道有 30 多大类,细分渠道有 4000+,不同外部引流渠道用户落地页分布及后续各环节跳转留存情况分析缺失;Web、App 10+、小程序 30+,内部多个应用的不同推广板块跳转关系多样化,急需内部渠道追踪分析工具。
神策分析云的渠道管理分析解决方案能够实现渠道效果的全端追溯,相关功能如下图拆解所示:
3.不同运营角色分析需求多样化
项目运营、平台运营、销售运营等多运营角色,不同角色的数据分析诉求不同。项目运营侧重对不同考试对应课程产品的售卖策略分析、营收业绩达成分析等;平台运营侧重对 App、小程序等应用进行用户流程优化分析、用户全生命周期分析等;销售运营侧重对用户线索的渠道分析、线索派发、销售跟进、业绩达成等环节的分析。为了满足多样化的数据分析需求,需要一个可灵活自定义的分析工具或平台。
神策分析支持事件分析、漏斗分析、留存分析、分布分析、间隔分析、用户路径、网页热力图、归因分析、属性分析等多种分析方式。其中,事件分析较为灵活,支持虚拟事件、自定义事件等,也支持自定义概览及邮件定时发送功能。
另外,综合考虑到私有化部署、技术成熟度、埋点能力、功能灵活性和扩展性、自建人力成本及机会成本太高等原因,该在线教育企业最终选择引进神策分析系统。
二、埋点的设计、管理、校验
神策分析部署完之后,需要快速补全过程数据,大量的埋点工作是必不可少的。在前期埋点工作的实践经验中,总结出如下的埋点设计、管理、校验方法:
1.埋点设计思路
(1)理解 Event-User 模型中的 Event
神策的底层数据模型是 Event + User 的事件模型,因此埋点在神策分析里被称之为“事件”。每个 User 实体对应一个真实的用户,用 distinct_id 进行标识,描述用户的长期属性,并且该用户可与其所从事的行为,即与 Event 进行关联。
为了用最简单的方式理解 Event 实体,可以借鉴中学语文老师讲的叙事文的五要素,即:人 + 时间 + 地点 + 方式 + 事情,也就是 who、when、where、how、what。
(2)事件设计要还原到业务场景
离开了场景的埋点设计一定会遭到业务同学吐槽的,因为很可能是不可用的。
比如在线教育业务场景下常见的事件“浏览课程详情页”事件,运营同学给你提需求时可能会说:“我想看下某个课程页面的被浏览次数”,如果你只把课程详情页的基本信息进行了埋点,那就是没有还原到业务场景中,或者是还原的不完全。
将用户“浏览课程详情页”的行为向前倒两步,可以看到这个行为序列:浏览课程倒流入口模板 → 点击课程卡片 → 浏览课程详情页。这时你会发现,课程详情页的前项页面是很多的,比如有:频道页-课程列表、首页-banner 推荐位、直播详情页-课程推荐模块、App 闪屏等,如果埋点时候不把前项页面名称和所属模块带上,那么行为信息是缺失的,总有一天运营同学还会给你提另一个需求:“怎么查看用户是从哪儿跳转到课程详情页的”。
(3)埋点设计文档
埋点文档要包括版本号管理、事件页面位置、触发时机、事件中英文名称、变量名称、SDK 说明等。 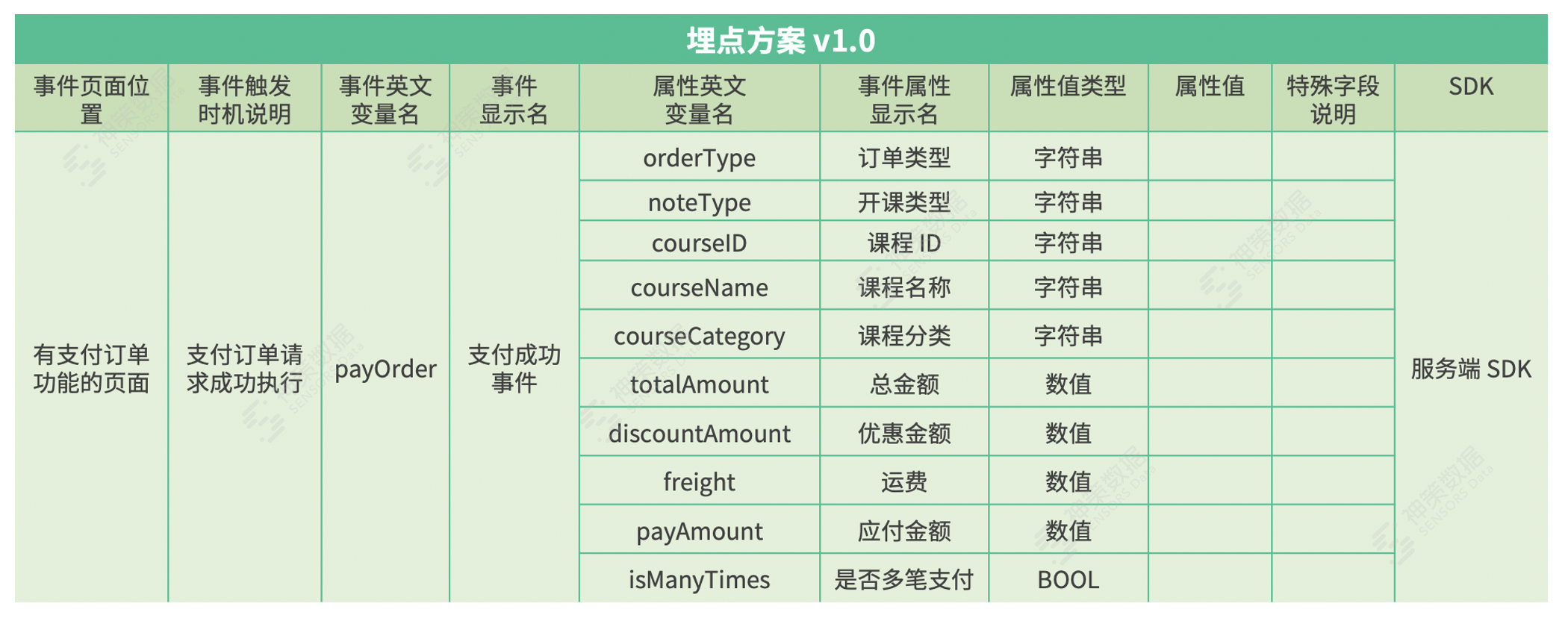 2. 埋点管理思路
2. 埋点管理思路
(1)埋点管理流程
埋点管理流程主要环节有:需求分析、埋点方案设计、需求评审、开发排期、埋点测试、上线回归、需求迭代闭环等环节,每个环节具体需要做什么,参见下方埋点管理流程图:  (2)需求梳理与验收
(2)需求梳理与验收
需求梳理环节要结合业务场景,对需求进行分析和拆解。拆解因素主要包括需求提交时间、业务部门、业务背景、需求场景描述、指标、指标定义、维度、用户行为、优先级、频次、验收标准。
需求验收主要是需求评审后需要确认研发、测试是否通过或者未通过的原因,主要包括相关分析功能、相关事件、测试是否通过或不通过的原因等。
(3)埋点进度管理文档
埋点进度管理文档是埋点开发里程碑节点 Check 工具,文档格式见下图。 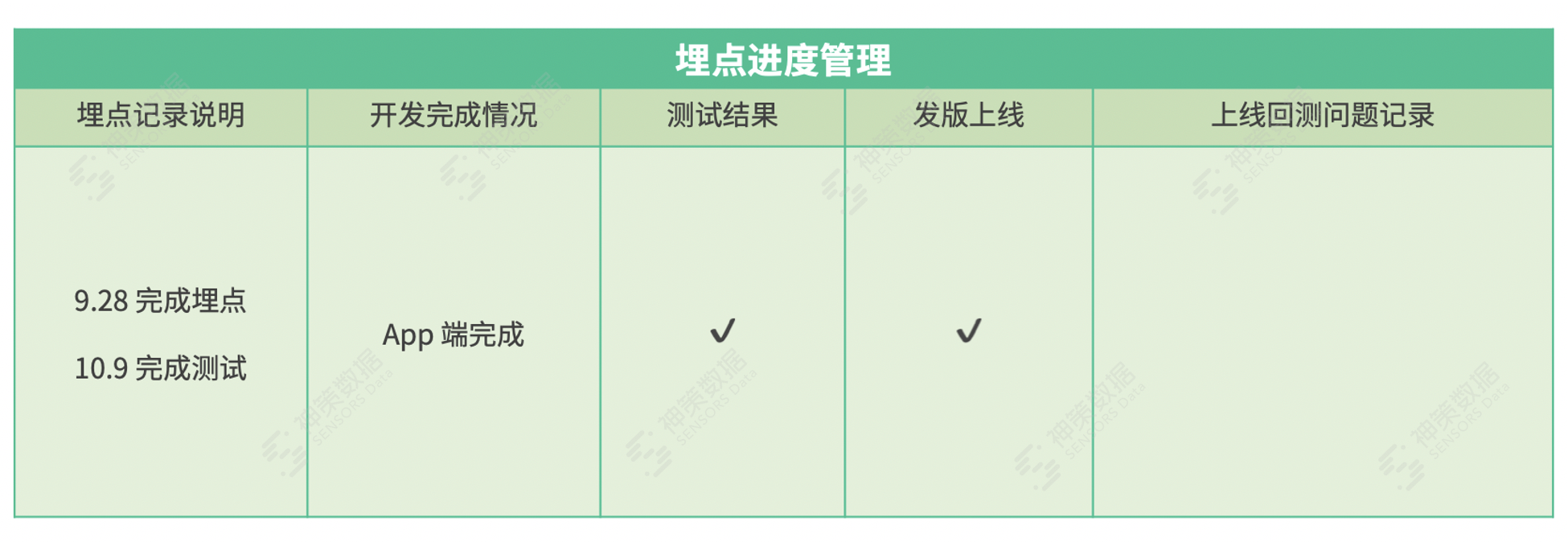 (4)开发流程优化迭代
(4)开发流程优化迭代
通过几次埋点迭代的推动之后,作者发现过程中总是不太顺畅,要么上线延期、要么耗费巨大沟通精力。企业的研发资源分布是按产品线进行布局的,Web 端、App、小程序、服务端都是专属对口的研发资源,如果每次埋点都直接和对应研发对接会存在两个问题:
· 负责埋点的产品要和公司 80% 的研发打交道,极大消耗个人精力;
· 各端研发人员日常工作节奏最熟悉的是其对应端的产品经理,方便把控版本节奏。
发现问题后,作者和团队对埋点开发流程进行了优化,不再直接和各端研发对接,而是把埋点需求拆解到各端产品经理,让其基于自身的产品版本进度穿插推进,当然这里还会面临各端上线不统一的问题,经过逐步优化迭代后,目前已经形成了较优的埋点开发流程。
3.埋点数据校验
(1)为什么要进行埋点校验
埋点校验的必要性有两点:
· 数据不准确造成数据权威性丧失,“用数据说话”可能就变成了一句笑话;
· 用户一旦对系统产生怀疑,便会种下一颗邪恶的种子,挽回成本大增。
(2)怎么进行埋点校验
数据校验是个磨人的体力活,因此建议各位小伙伴在进行数据校验前先调整好心态,选定靠谱用户试用,通过他们的经验能快速发现问题,与业务系统数据、第三方平台做对比发现问题,优先排查主数据(订单、用户数据等)。
常见的埋点校验思路如下:
· 先排除是统计口径问题造成的数据误差;
· 对数据链路进行校验;
· 校验上报的事件及属性是否符合埋点设计文档;
· 统计排查事件属性是否存在大量未知情况
三、数仓与神策分析结合构建 MVP 方案
1.数据流转链路
神策分析和数仓打通的数据流转链路如下图所示:  2.神策埋点数据通过订阅分发机制同步数仓
2.神策埋点数据通过订阅分发机制同步数仓
神策分析的架构设计是开放式的,可以通过订阅实时数据来满足更多使用场景。服务端接到一条 SDK 发来的数据后,会对数据做一些预处理并将数据写入到消息队列 Kafka 供下游各类计算模块使用。
订阅数据要求如下:
· 启动订阅的机器需与部署神策分析的机器在同一个内网,且必须可以解析神策分析服务器的 host;
· Kafka 客户端版本要选择与部署的神策分析兼容版本;
· 只有私有部署版支持通过 Kafka 订阅数据。
订阅参数:  3.数仓加工处理后数据定时导入神策
3.数仓加工处理后数据定时导入神策
神策架构的优势就是其开放性,当然也提供了多种数据导入工具下,各导入工具对比分析可以参见下表: 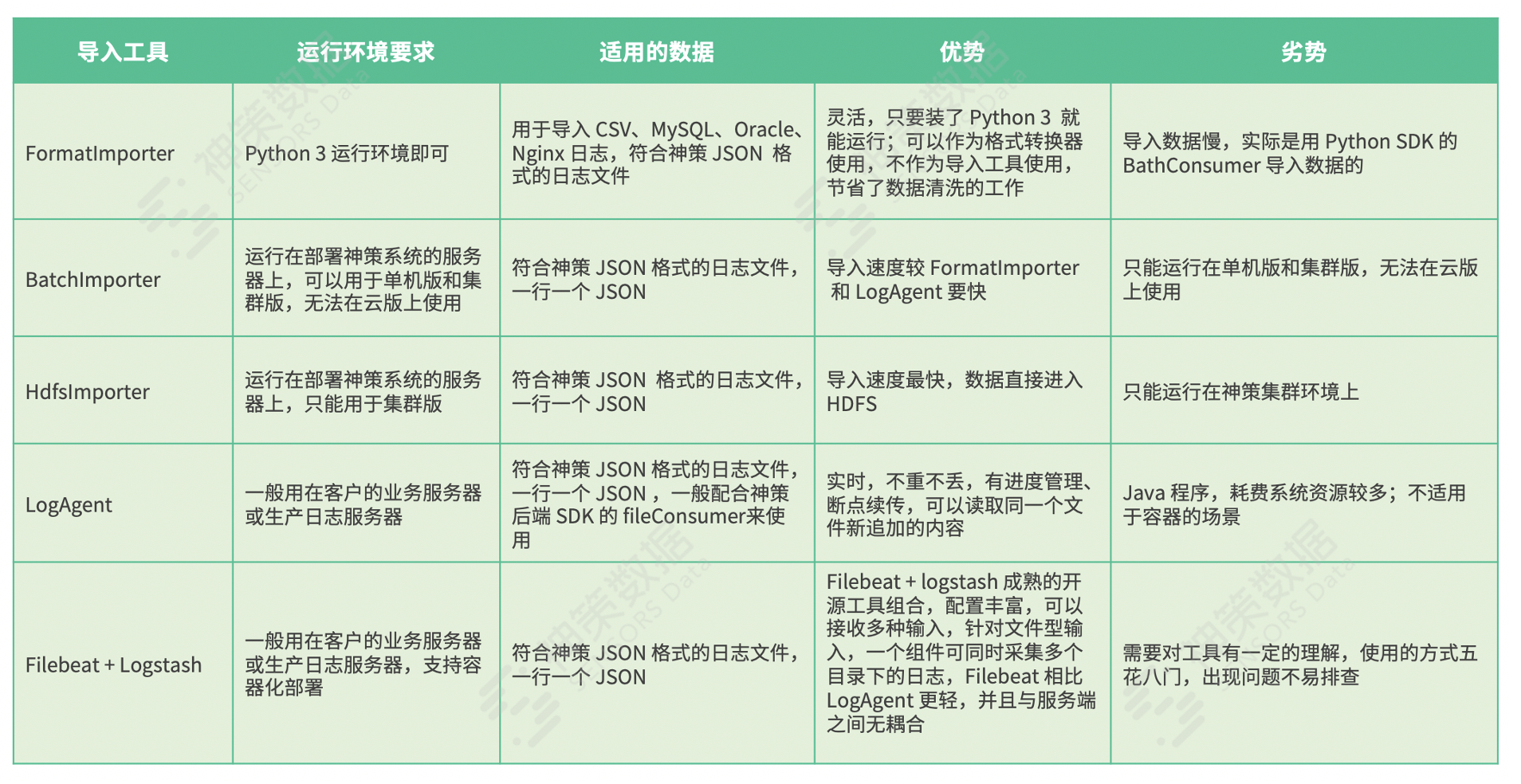 该在线教育企业的数据同步方案如下:
该在线教育企业的数据同步方案如下:
· T+1 处理机制,一般是在凌晨进行数据加工处理,并导入神策系统; 为了保证内部 Data pipline 工具的统一化,基于 spark 重构了 FormatImporter 方法;
· 同步操作脚本自动化,加入统一 workflow 进行管理和监控。
以上便是该在线教育企业的数仓与神策分析共同构建数据化运营平台的完整方案。
点赞(0)



说点什么
全部评论
