
利用深度学习来提升语音增强效果和鲁棒性,已成为实时音视频通信领域研究的热点之一。钉钉蜂鸣鸟音频实验室提出了一种新的窄带滤波网络架构,可大幅提升去噪和去混响联合语音增强效果,提升音频质量,相关论文已被语音领域顶会INTERSPEECH 2022收录。
INTERSPEECH是由国际语音通讯协会(ISCA)创办的顶级学术会议,也是全球最大的综合性语音领域的科技盛会,在国际上享有极高盛誉并具有广泛的学术影响力,历届INTERSPEECH会议都倍受全球各地语音研究领域人士的关注。
不同于目前普遍以全频带语音信息作为输入的实现方式,钉钉蜂鸣鸟音频实验室提出的窄带滤波网络架构,是以每个频带信息作为输入,让每个频带共享网络参数,并引入听觉研究领域的频-时调制谱感受区(spectro-temporal receptive fields,STRFs)。
窄带滤波网络架构的目的,是从本质上提高输入的频带信息对语音和非语音的鉴别力,从而大幅提升窄带滤波网络消除噪音和混响的算法效能。
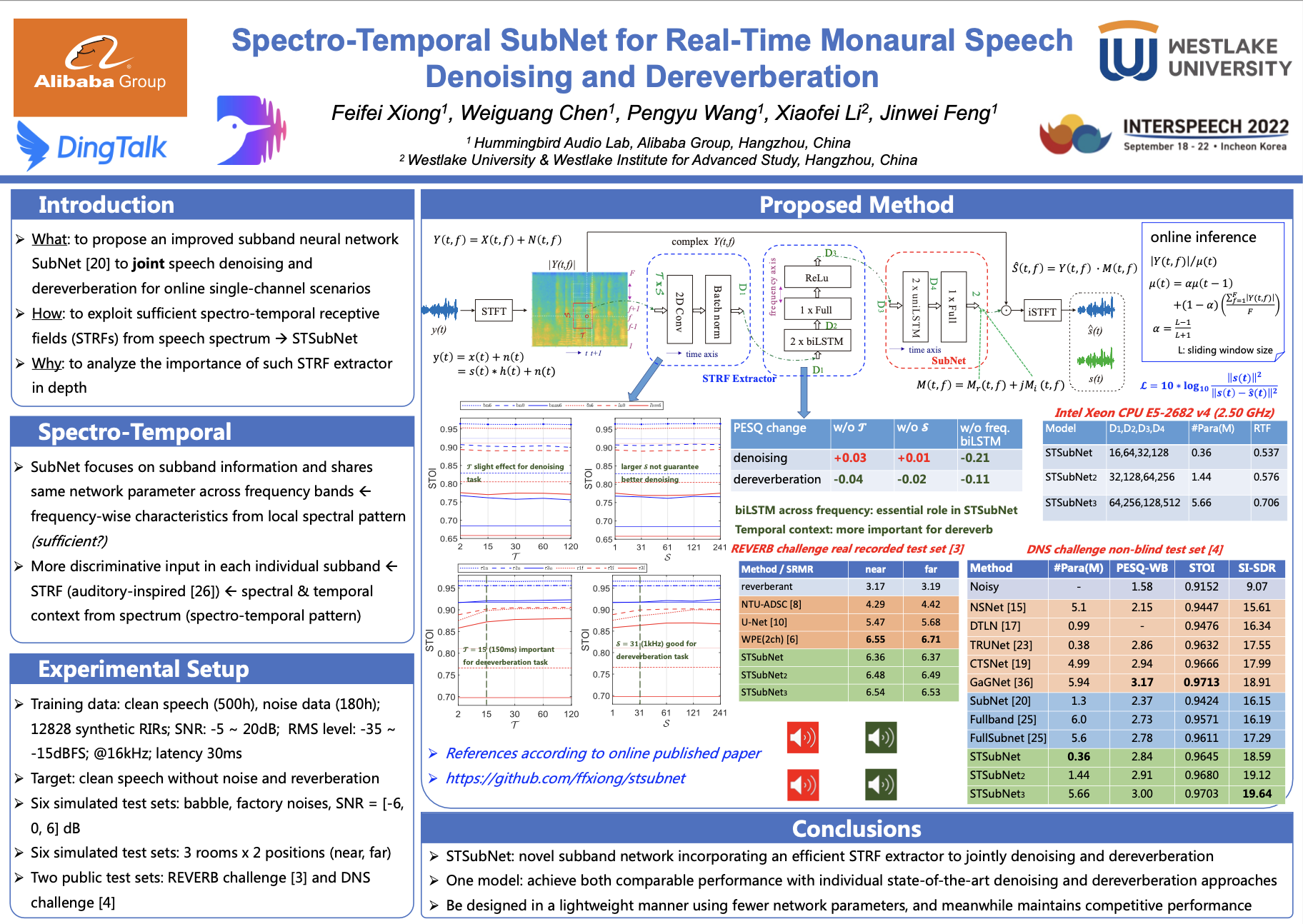
测试证明,相比带宽滤波网络,这种轻量的模型能得到更好的实时单通道语音增强效果,可提升20%的语音质量,并减少约70%的网络模型大小,大幅降低推理的复杂度,可应用于在噪杂的办公室、大会议室等复杂场景中提升语音质量。
值得一提的是,该研究也验证了仅用一个神经网络模型进行多项语音增强任务的可行性。过去,在音频链路中部署过多不同神经网络模型,会导致消耗过多的运算资源,而采用一个模型,将有效缓解神经网络在落地过程中遇到的难点。
据介绍,钉钉蜂鸣鸟音频实验室提出的关于「兼容指向型麦克风的波达方向与距离的联合估计框架」的论文一并入选INTERSPEECH,该框架是用于提升声源定位的精度和效果。
实验室研究人员表示:“波达方向与距离估计对于声源定位技术是相当关键的信息。我们提出的算法首先对声音信号传播进行建模,融合不同传感器/麦克风类型(全向和指向型),再利用稀疏贝叶斯学习框架准确地联合判断出波达方向与距离信息,可应用于多声源定位。”
实验证明,在双声源场景下,当信噪比(signal-to-noise ratio SNR)达到8dB,波达方向估计误差即能控制在1度以内,距离估计误差能控制在0.1米之内。
钉钉蜂鸣鸟音频实验室旨在用传统信号处理结合深度学习算法,来解决实时语音通信碰到的复杂问题,提升钉钉会议、直播以及合作会议硬件的产品体验,并探索下一代音视频形态。其重点研究方向包括音频3A算法、单通道/多通道语音增强、声源定位等。
点赞(0)
你可能喜欢



说点什么
全部评论
